Learning deeply about computer networking can lead you to be a better software engineer. I argue in favor of that because all the software we produce/use/maintain uses the network to communicate.
Very often we trust stuff we think we know, and computer networking is one of them. The cloud or even “full application platform” (such as k8s) may increase this knowledge gap for good and for bad.
Here are the most useful resources I think might help you understand how computer networking works.
Here at Globo, we have as our mission to build resilient systems to provide an optimal experience for our domestic and international customers, allowing them to watch their favorite international or local tv show, a soap opera, or any of our live streaming channels on globoplay.
The architecture supporting globoplay’s media platform heavily relies on open-source software such as GNU/Linux, nginx, tsuru, kubernetes, clappr, nginx, on-the-fly packaging and much more. Another exciting aspect about Globo is that we built and manage our own CDN. Such a task pushes us to broaden our knowledge and understanding around Brazil’s networking infrastructure.
Nowadays, people are expecting to stream on any device they own. This means that we need to support most of these devices. There are hundreds of smartphones, dozens of smart TVs, many tablets, browsers, casters, etc. Providing a steady and successful playback experience in this scenario inevitably adds a lot of complexity to the architecture.
landscape
We’re live-streaming the famous program Big Brother through the Internet and broadcasting it into the air as well. In one of the days, we reached 2 million simultaneous users watching the BBB live stream. To serve these many users, we must be present in the majority of stream-capable platforms.
Before we discuss the challenges we face dealing with this plethora of devices, here’s the breakdown of play hit and watch session percentage grouped by major platform.
The data from one week in January, 2021. Play metric means the percentage of plays for a specific device. Playtime represents the fraction (%) of whole-time watched by a given platform. Big screen accommodates all casters and HTML also counts mobile browsers.
In the US, the market-share seems to gravitate around the casters (also k nown as OTT devices like FireTV, Roku, ATV, etc). In contrast, here in Brazil, we have mobile devices and connected TVs sharing a lot of home presence. We have a diverse environment of Connected TVs brands as well as a significant number of old TVs that run legacy and outdated firmware/OS versions.
On the Big Brother case, the big-screen performed fewer plays, but people kept watching on it for longer sessions. It could be due to the convenience that these devices offer, but it’s hard to draw a conclusion.
This data may differ from other players in Brazil. However, here are some observations for the context of Brasil:
Netflix, due to its premium VOD only nature,
Youtube, because they’re present natively on most platforms,
Twitter / Facebook, their massive presence mostly on mobile
Although it wouldn’t be unexpected, if the data presented here align with these players.
challenges
While having people watching everywhere sounds good, it also poses a hard technical challenge. To support the majority of devices, we need to adjust our platform in almost every component of its workflow.
Here we list some of the problems we faced and how we fixed them:
http protocol
HTTP Cookies
problem: some devices can’t manage cookies
solution: persist data over URI or HTTP headers
HTTP CORS
problem: some native players don’t follow all the cors specification
solution: adapt for their usage
chunked transfer
problem: a specific device fails silently dealing with chunked transfer
solution: buffer the intermediate response and serve the full file
media encoding
video frame rate
problem: mixing different frame rates (i.e. 30fps and 60fps) causes glitches on rendition swap in some players
solution: offer fixed frame rate ladder for them
audio sampling
problem: 48khz sampling causing audio glitch/sync on some devices
solution: stick to 44.1 khz
aes hls encryption
problem: some devices handles aes hls keys as if they were always at the same level as the master variant (if they aren’t, then it’s a 404)
solution: put the full URI for each key or always have your variant in the same level as your master
syncing by hls media sequence
problem: some players use the hls media sequence attribute to sync among the renditions
solution: always sync your media sequence
high resolutions
problem: some devices won’t be able to play high resolution renditions (even if they advise otherwise)
solution: filtering out resolutions based on observed capacity
network
Brazil is a continental country with sub-optimal internet infrastructure. One way to offer a smooth experience for media streaming users is to take the content closer to them. We are continually expanding our footprint with new edges, open caches, ISP, IX, etc.
Although we have an average broadband of 24 Mb/s, we still have a lot of users down below the 2 Mb/s marks. It might be due to the ISP fragmentation (Brasil has at least six thousand of them).
We improved our streaming QoE by adding a 144p rendition within our current ladders. In a live streaming, such a rendition may require around 200kpbs which consumes circa 77MB per hour.
Such a complex scenario made us introduce an extra congestion control level. When we notice that a group of users, behind an ISP, started to fill their link to our CDN, we eagerly adjust the renditions’ suggestion to these users. At the point where the link starts to decrease its saturation, we also re-adjust the suggested bitrates.
In this server-side “ABR” we act much more preventable than in the player’s ABR algorithms or the (almost reactive) TCP mechanism.
it’s all entertainment
Dealing with outdated devices, varying Internet speed, latency, and bandwidth, plus the already complex media streaming surroundings requires teams to be well-integrated. People working together help to alleviate the hard task of debugging in this environment.
Brazilians love to spend time on the Internet. The quantity of devices (brands, OSes, build year, etc) and the complex Internet infrastructure creates opportunities to be creative while designing systems to support Brasil’s context.
I was following some interesting discussions about how no one should trust a print screen of a tweet, and it got me thinking regarding how to overcome such a challenge.
What if somehow we could attach a verifiable piece of text (or image QR code) to a tweet that could quickly disprove a fake print screen or still optimistically could point that this print might be legit.
simulating a verifiable tweet card
I thought about using HMAC to solve this problem, where the secret is something that only Twitter knows and it’s tied to each user. Every tweet must have an SHA 256 signature, signature = HMAC(user.secret, tweet).
For the sake of UX/UI, this signature can show only its first ten characters, a short hash and it still retains a good number of permutations (16^10).
Now when you see a print screen claiming that @someone told “this and that” you can go to somewhere like twitter.com/check and type the username, the message plus its alleged signature and verify whether it’s fake or might be legit.
Sounds good and simple, done:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Of course not, such an idea needs to be refined and proven to be safe. I foresee many challenges, one of them being, let’s say someone is trying to check a print however this person might not be able to replicate the images, emojis, special characters or even to match the number of spaces/newlines.
For that reason, a kind of allow list filtering out anything else might be in hand. The question is, what characters such a set would hold? The basic Latin character set [a-z, A-Z] is not enough. We have special accent characters in languages such as Portuguese, Spanish and French. And languages such as Hebrew, Japanese, Chinese are best represented by Unicode/UTF-8 characters.
Also, since I’m not a security specialist in any capacity, I don’t know what happens if the secret remains the same over time with a ton of tweets and signatures exposed. Is it possible for an observer to break this thing?
Well, that’s my silly approach to try to fight the Fake Tweet Print Screen. What do you think? Is it feasible? Is it even necessary to build such a system? Or is it just a plain stupid idea?
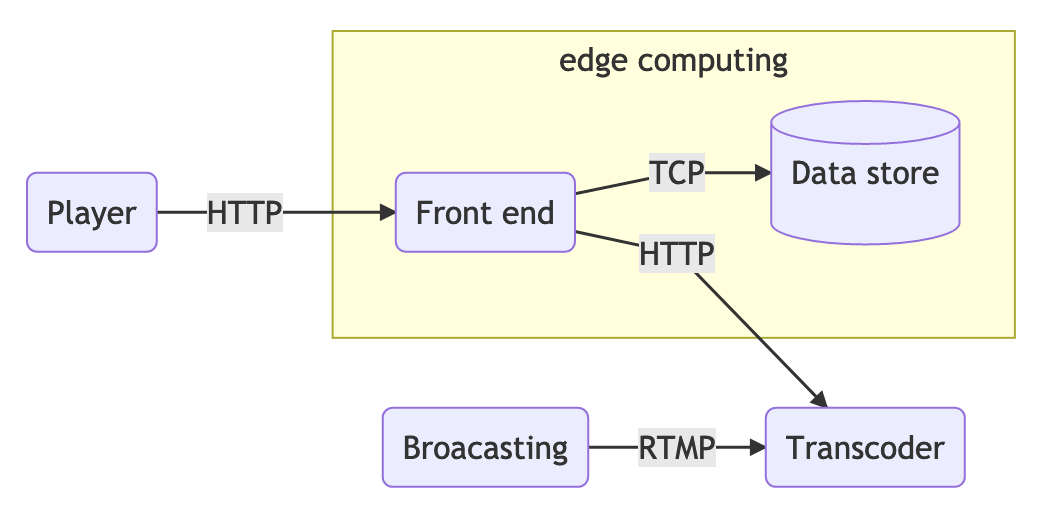
This is the last post in the series, now we’re going to design an edge computing platform using Lua, Nginx, and Redis cluster. Previously, we explained how to add code, not dynamically, in nginx.
Platformize the computations
The platform is meant to provide a way to attach Lua code dynamically into the edge servers. The starting point can be to take the authentication code and port it to this solution.
At the bare minimum, we need a Lua phase name, an identifier and the Lua code. Let’s call this abstraction the computing unit (CU).
If we plan to add a computing unit dynamically to the NOTT, we need to persist it somewhere. A fast data store for this could be Redis.
We also need to find a way to encode the computing unit into some of the Redis data types. What we can do is to use the string to store the computing unit. The key will be the identity and the value will hold the Lua phase and code separated by the string “||“.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
The platform needs to know all of the computing units, therefore, we need to list them. We could use the keys command but it can be very slow depending on how much data we have.
A somewhat better solution would be to store all the identities in a set data type, providing an O(N) solution, where N is the number of CUs.
KEYS pattern would also be O(N) however with N being the total number of keys in the data store.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Now that we know how we’re going to encode the computing unit, we need to find a method to parse this string separated by || and also a process to evaluate this string as code in Lua.
To find a proper and safe delimiter is difficult, so we need to make sure that no Lua code or string will ever contain ||.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
To split a string we’ll use a function taken from Stackoverflow and for the code evaluation, Lua offers the loadstring function.
But now some new questions arise, what happens if the code is syntactically invalid or when the CU raises an error? and how can we deal with these issues?
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
To deal with syntax errors, we need to validate the returned values from the function loadstring where the first value is the function instance and the last is the error.
And to protect against runtime error, Lua has a builtin function called xpcall (pcall meaning protected call) that receives a function to execute and a second argument which is an error handler function.
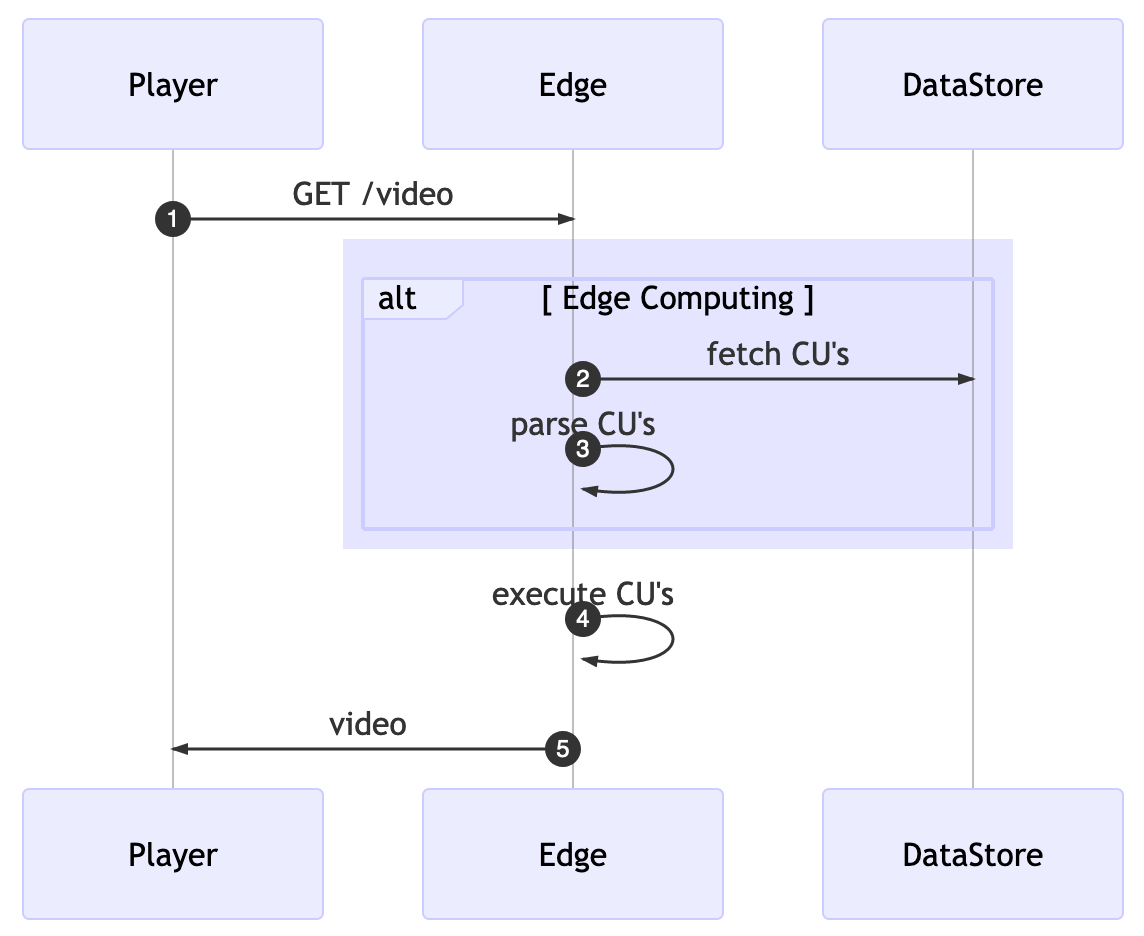
With all this in mind, we can develop the core of our platform. Somehow we need to get all the computing units from Redis, parse them to something easier to consume and finally, we can execute the given function.
Before we start to code, we can create a prototype that will replicate the authorization token system we did before but now using Redis to add and fetch the computing unit as well as shielding the platform from broken code.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
To test these lines of code, we can go to the terminal and simulate calls to the proper nginx location. Therefore we can understand if the expected behavior is shown.
Since we’re comfortable with our experiment, we can start to brainstorm thoughts about the code design and performance trade-offs.
Querying Computer Units
The first decision we can take is about when we’re going to fetch all the computing units (CUs). For the sake of simplicity, we can gather all the CUs for every request but then we’re going to pay extra latency for every client’s request.
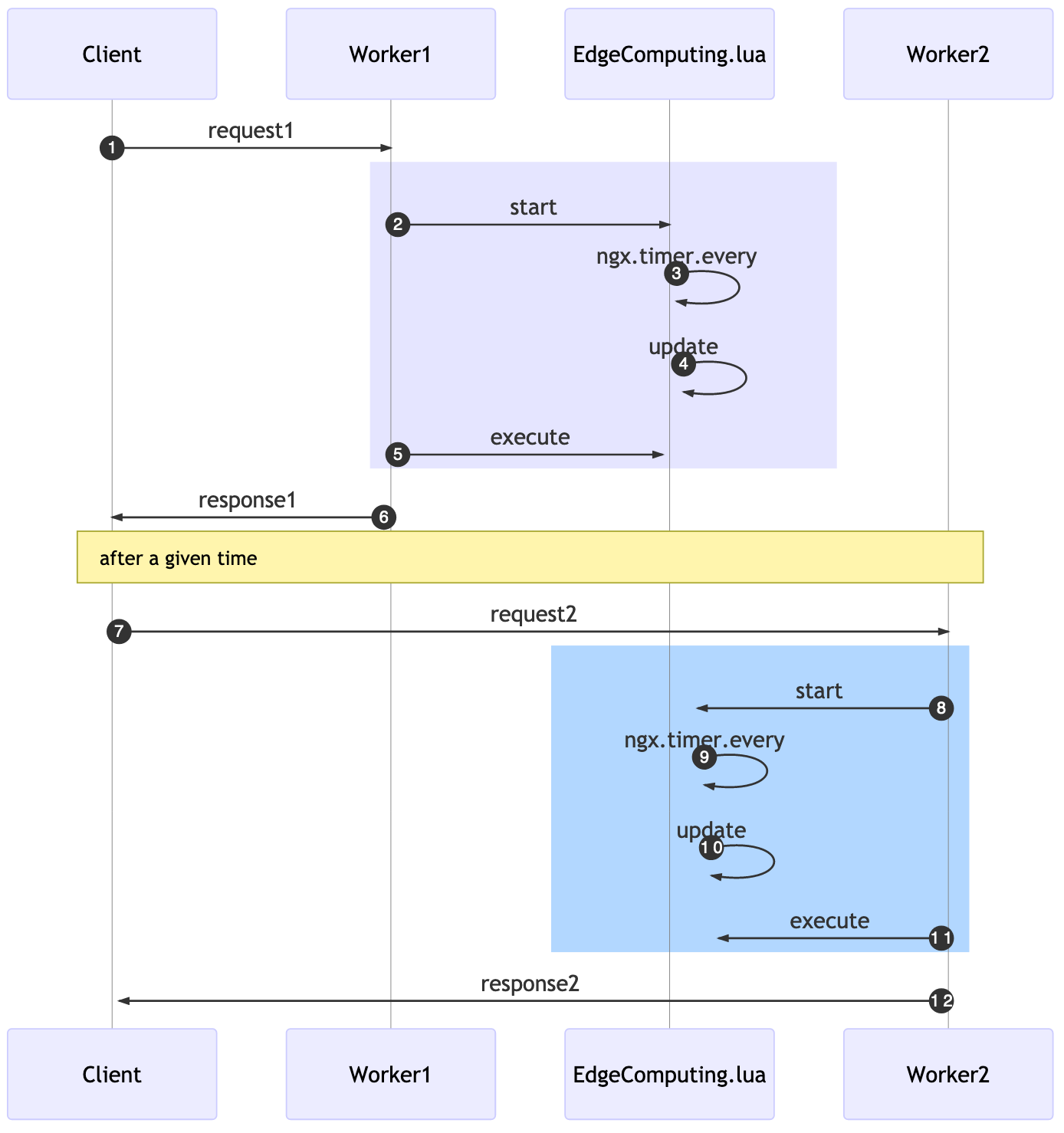
We’ll move the fetch and parse logic to run in the background. With that running periodically, we then store the CUs into a shared memory where the edge computing core can lookup without the need for additional network connections.
Openresty has a function called ngx.timer.every(delay, callback), it runs a callback function every delay seconds in a “light thread” completely detached from the original request. This background job will do the fetch/parser instead of doing so for every request.
Once we got the CUs, we need to find a buffer that our fetcher background function will store them for later execution, openresty offers at least two ways to share data:
a declared shared memory (lua_shared_dict) with all the Nginx workers
encapsulate the shared data into a Lua module and use the require function to import the module
The nature of the first option requires software locking. To make it scalable, we need to try to avoid this lock contention.
The Lua module sharing model also requires some care:
“to share changeable data among all the concurrent requests of each Nginx worker, there is must be no nonblocking I/O operations (including ngx.sleep) in the middle of the calculations. As long as you do not give the control back to the Nginx event loop and ngx_lua’s light thread scheduler (even implicitly), there can never be any race conditions in between. “
The usage of this edge computing lua library requires you to start the background process and also to explicitly call an execution function for each location and lua phase you want to add it to.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
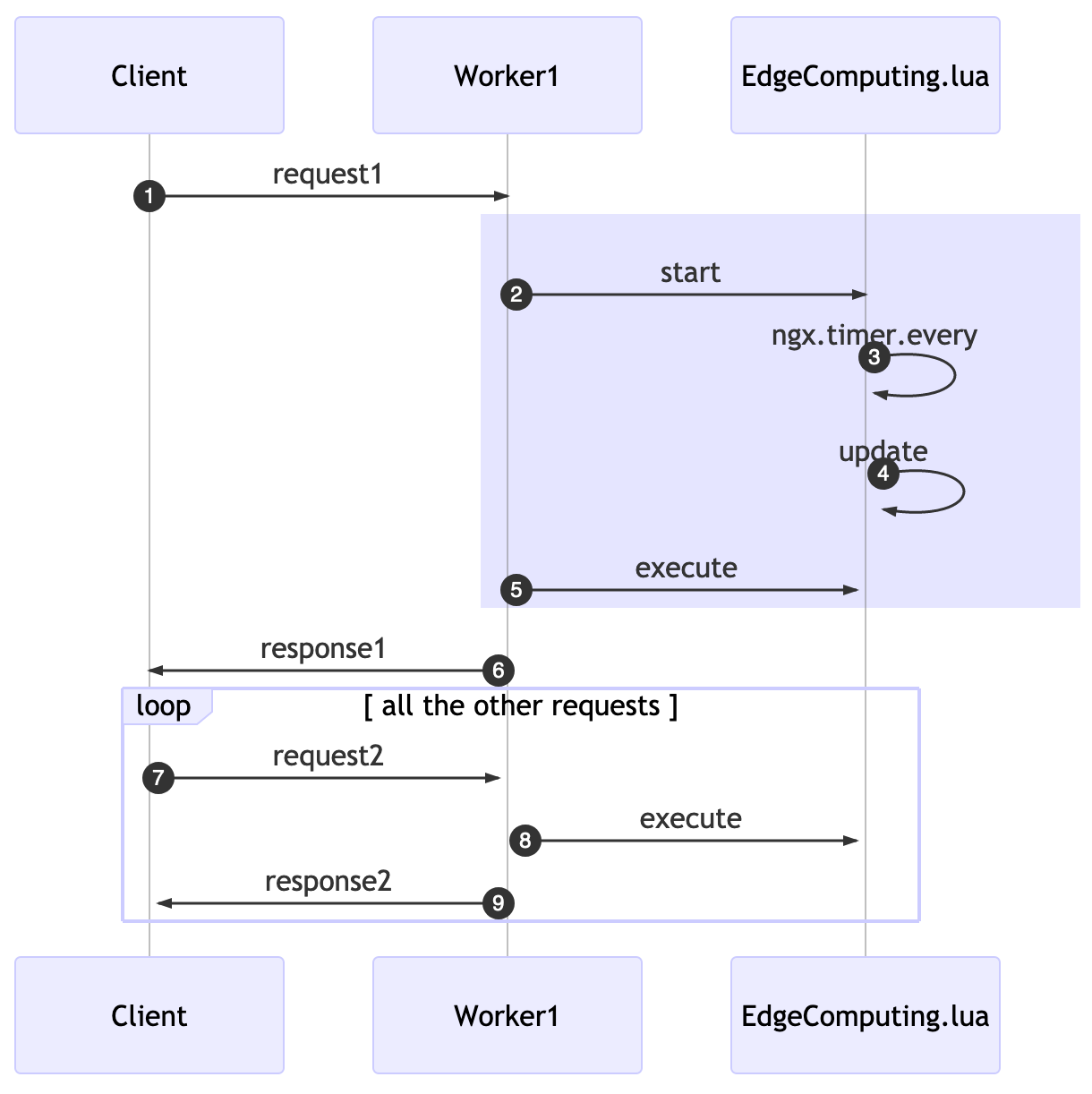
In the past example, we started, on the first request, at the rewrite phase, this will also initiate the background job to update every X seconds.
On the access phase, we’re going to execute the available CUs. If a second request comes in, it’ll “skip” the start and just execute all the cached CUs.
While using these APIs solve our challenge of adding unnecessary latency, it comes at a price: now when we add a new CU to the data store, it might take X seconds to be available for workers.
The rewrite_by_lua_block was used because it’s the first phase where we can start a background job that can access cosockets and works with lua-resty-lock (a library used by resty-redis-cluster).
A funny behavior will happen, related to the eventual consistency nature of this solution: if a client issues a request1, in a given time for a Worker1, later the same user does another request2 and a different Worker2 will accept it. The time in which each worker will run the update function will be different.
This means that the effective deployment of your CUs will be different even within a single server. The practical consequence for this is that the server might answer something different for a worker in comparison to another one. It will eventually be consistent given the x seconds delay declared as update interval.
Adding the CU via the Redis cluster will make it work.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Let’s list some of the possible usages for this platform so we can think a little bit ahead of time.
access control – tokens, access control, origin
change response
decorate headers
generate content
traffic redirect
advanced caching
…
The options are endless, but let’s try to summarize the features that we didn’t add to the code yet.
When we implemented the request counter we used redis as our data store so it’s safe to assume that somehow the CUs might use redis to persist data. Another thing we could do is to offer sampling, instead of executing the task for all requests we could run it for 3% of the them.
Another feature we could do is to allow filtering by the host. In this case, we want a given CU to execute in a specific set of machines only, but we also can achieve that in the CU itself if we need to.
The persistence needs to be passed for the CU, we can achieve that by wrapping the provided raw string code with a function that receives an input and pass this argument through the pcall call.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
We’ll have access to the edge_computing in our CUs as if it was a global variable.
And finally, we can mimic the sampling technique by using a random function. Let’s say we want a given CU to be executed 50% of the time.
We need to encode the desired state at the datastore level and before we run the CU, we check if the random number, ranging from 1 to 100, is smaller or equal to the desired sampling rate.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Pure random distribution is not the most adequate, maybe in the future, we can use an algorithm similar to the power of two choices.
Future
Any platform is a complex piece of software that needs to be flexible, accommodate many kinds of usage, be easy to use, be safe and it still needs to be open for future innovation/changes such as:
a control plane where you can create CUs using UI
if the execution order is important then change the current data types
add usage metrics per CU
wrapper the execution with a timeout/circuit breaker mechanism
I hope you enjoyed these blog posts, they were meant to mostly show some trade-offs and also to deepen the nginx and Lua knowledge.
This is the second post in the series where we develop an edge computing platform. In this post, we’ll add some code/behavior to the front end servers. Here’s a link to the previous entry.
Add code inside the front end
The OTT service we did before don’t employ any kind of authentication thus the users can watch the streams for free. To solve this authentication issue we can add Lua code embed into nginx.
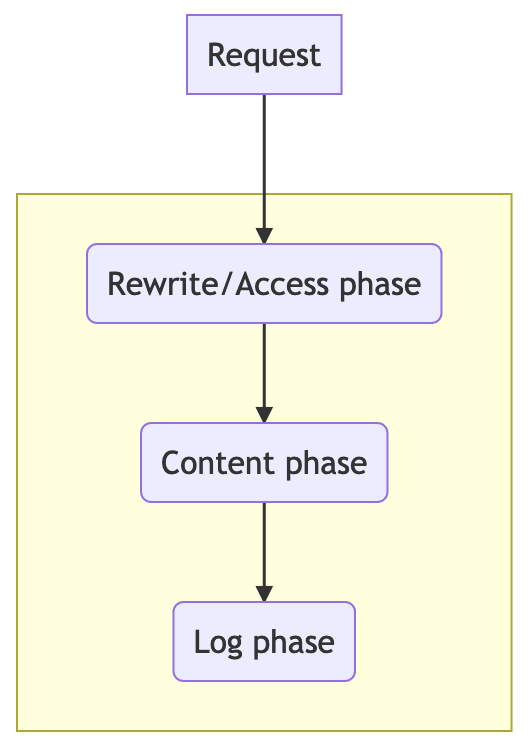
To run Lua code inside nginx you need to understand a little bit of the request phases within the server. The request will travel across different stages where you can intercept it using Nginx directives and add the code.
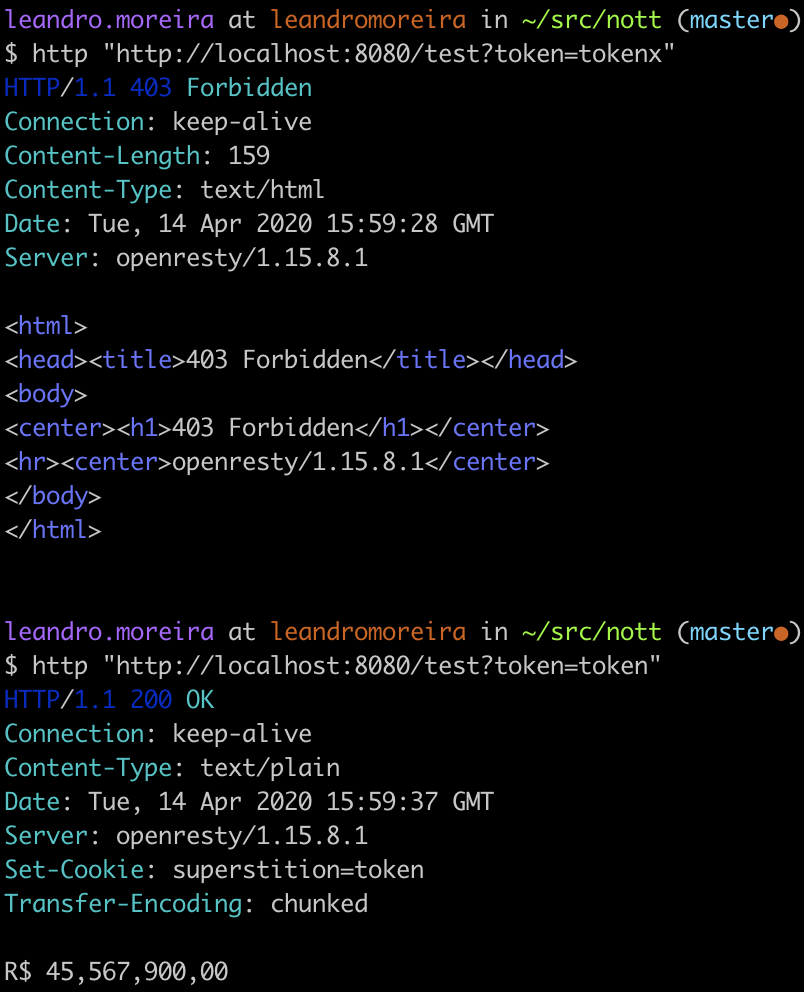
Just for the sake of learning, the authentication logic will be a straightforward token system. During the access phase, we’ll deny access for those with no proper authentication. Once a user has the required token it’s going to be persisted in form of a cookie.
Fixed token with no expiration is unsafe for production usage, you should look for something like JWT.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
The edge server can run useful behavior/code, now let’s laid out some examples that demonstrate the power we can have while executing functions at the front end.
Suppose a hacker, behing the IP 192.168.0.253, is exploting a known issue, that is going to be fixed soon. We can solve that by forbiddening his/her IP. Adding lua code, to the same phase, can fix this problem.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Nginx has the deny directive to solve this problem although it doesn’t allow a dynamic way to update the IP list. We would need to reload the server every time we want to update the IPs.
It’s wanted to avoid different domains to consume our streams, to prevent that, we’re going to examine the referer header and reject all the requests not originated from our domain.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
To on-the-fly change the response from the backend, we’ll add a custom HLS tag in the playlist.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
To decorate the HTTP headers, we’ll attach new ones exposing some metrics from the server and for that matter, it can rely on the ngx.header[‘name’] API.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Finally, we’ll count how many requests a given user (based on her/his IP) does and expose it through a custom HTTP header. The counter was stored in Redis.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
All this is working, if you want, you can test it by yourself.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters







You must be logged in to post a comment.